Ingestion Configuration
Navigate to the AWS Lambda console and create a new function

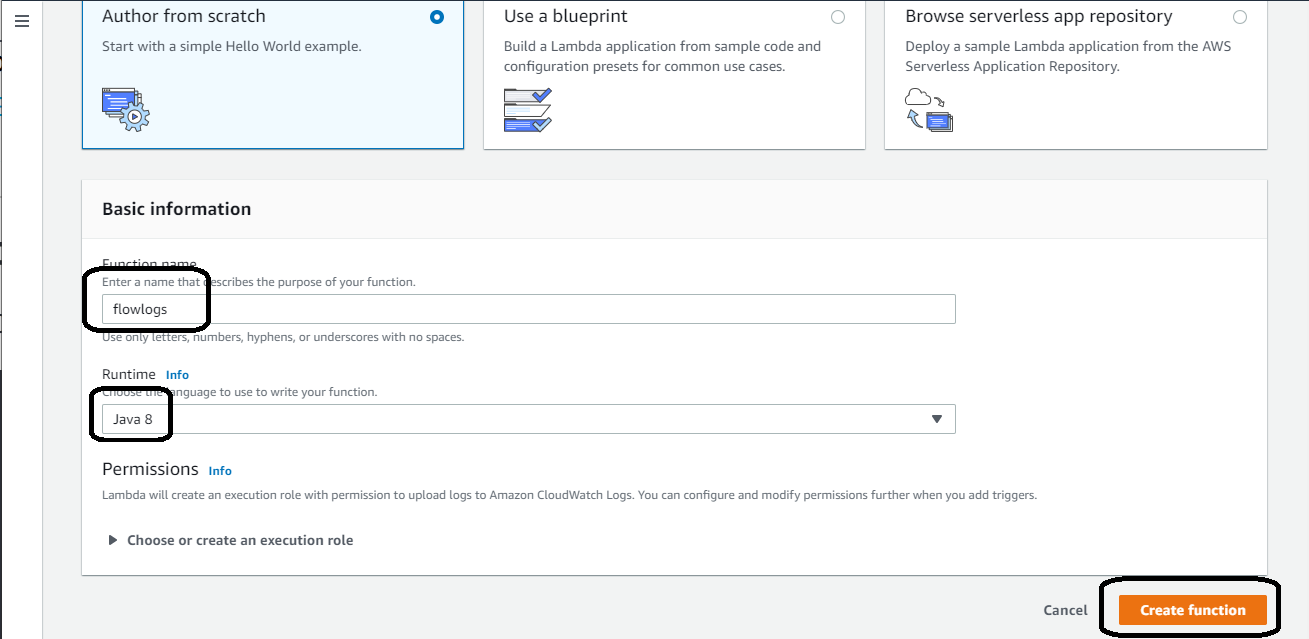
Select “Author from scratch” - default, give the function the name “flowlogs” and select “Java 8” for the run time as the jar file used in this lab was built using that runtime engine.
Update Basic settings
Here you’ll assign an execution role, update handler setting and configure timeouts and memory.
Scroll down to the “Basic setting” section and click Edit. 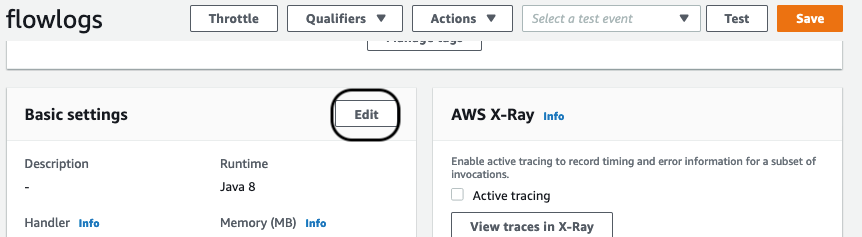
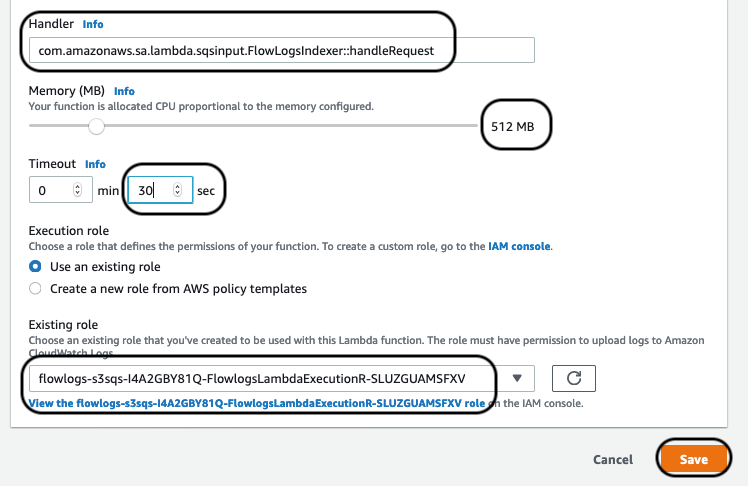
For the Handler, paste in the following:
com.amazonaws.sa.lambda.sqsinput.FlowLogsIndexer::handleRequest
Choose 30 seconds for the timeout and keep the function at 512MB.
Choose existing role and select the role matching “*FlowlogsLambdaExecution*”. Save the configuration.
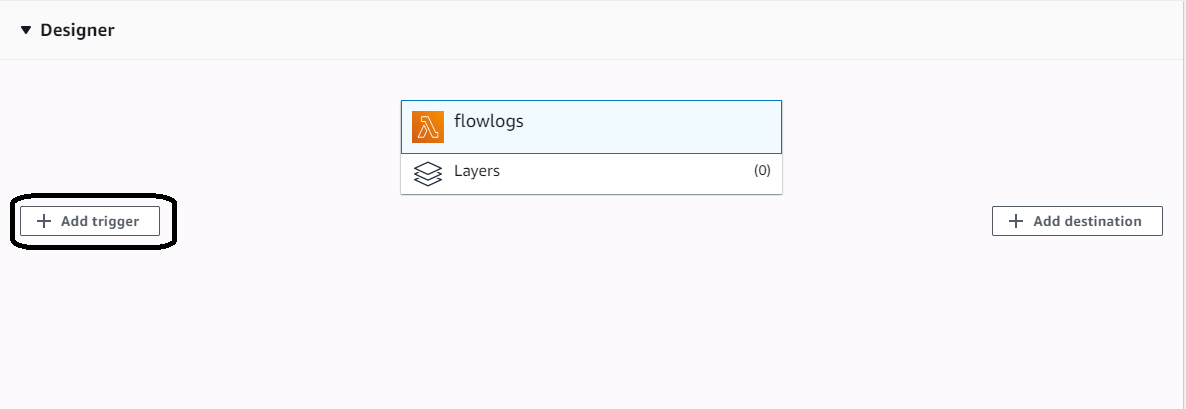
After you create the execution role for the function, you need to trigger it. Click on the “Add trigger” button.
Select SQS as the event source and clicked on it
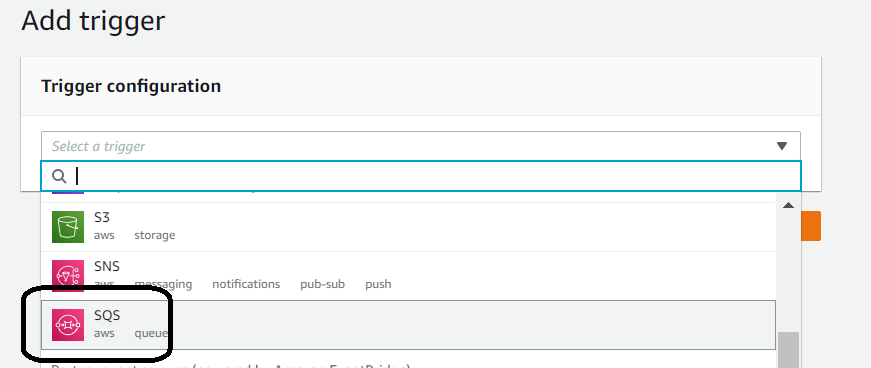
This exposes the final configuration. If you are not using a fresh account, select the SQS queue that matches what was created in your CloudFormation template as seen here in the s3sqs stack resources tab:

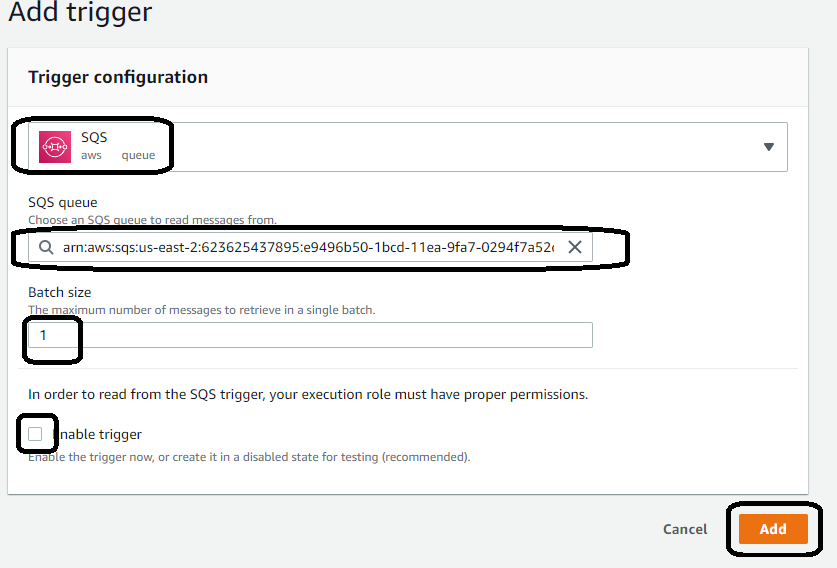
Make sure you do NOT enable the trigger and keep the batch size set to one. You will configure concurrency later on in the lab to deal with throughput.
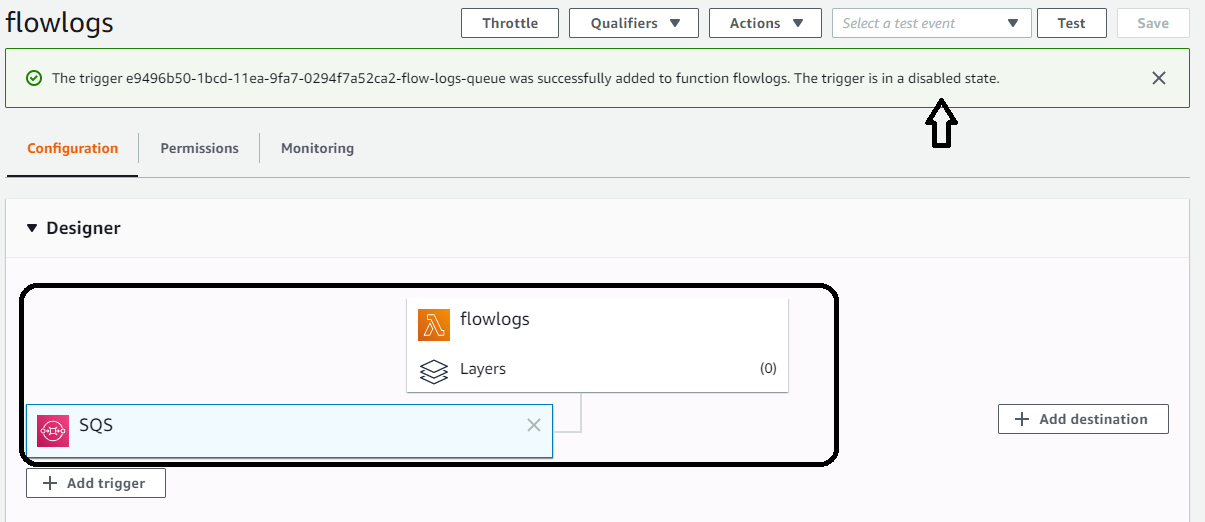
Once you have added the trigger, you will see the following. The trigger needs to be disabled while you configure the rest of the function:
Provision concurrency settings
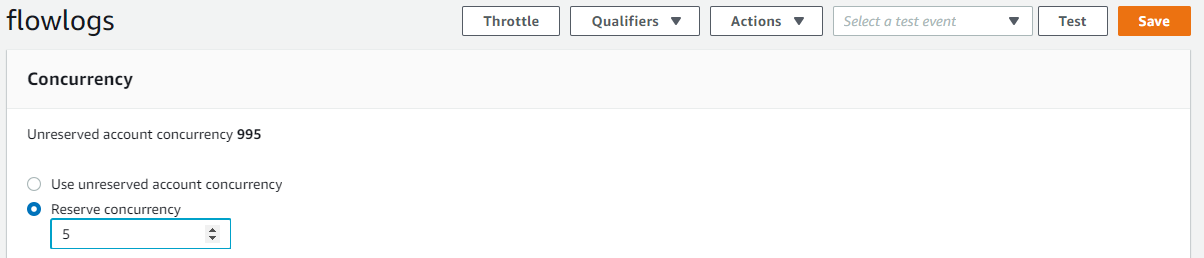
Click on the flowlogs section to expose the settings and scroll down to Concurrency section. Set reserve concurrency to 5 and save the setting.
Provision VPC settings
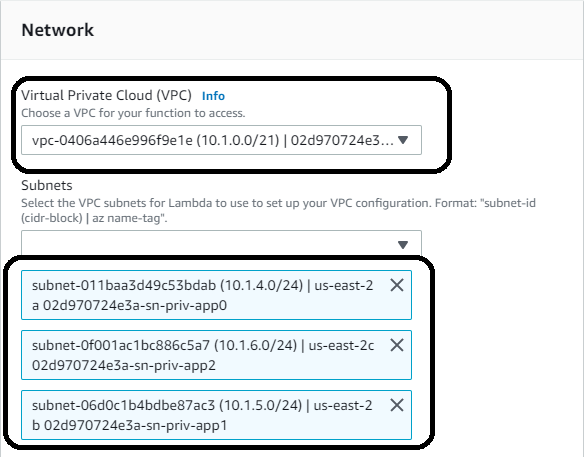
Since you run this solution in VPC, you will not use the public APIs. Lambda is created using ENI / private endpoints so that the Lambda traffic can stay private. Scroll down to the VPC settings and select the VPC created by this lab (detail are in the network stack under AWS CloudFormation. Select the private subnets.
Next, setup the security groups using the security group labeled like “*SQSPrivate*” and save the configuration.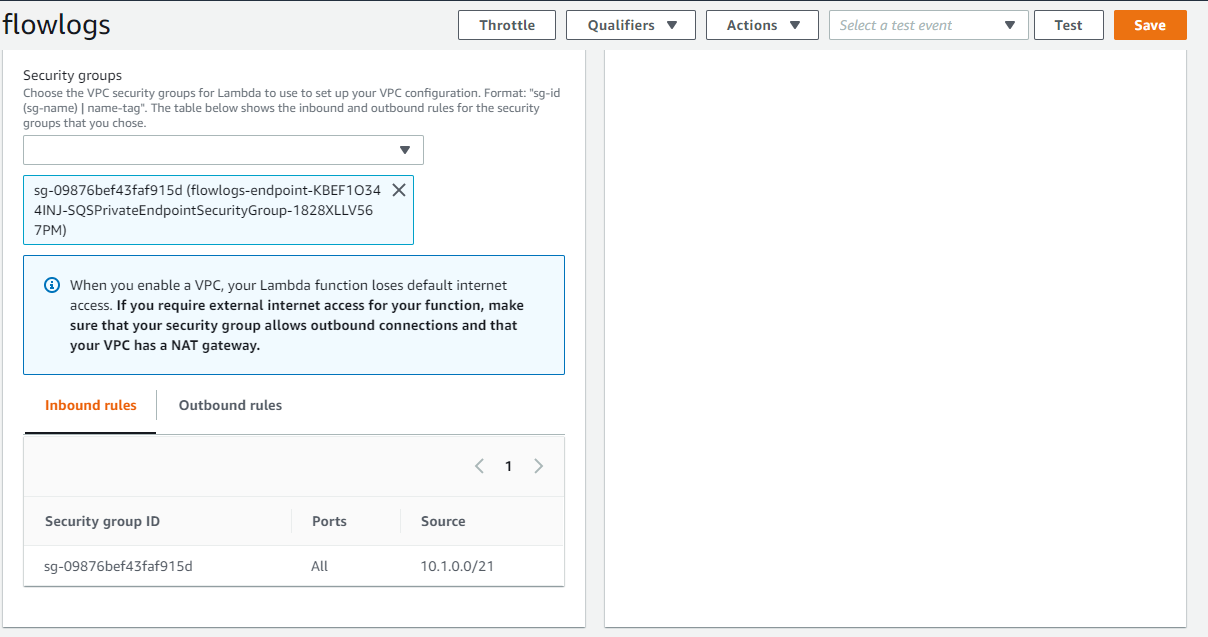
Configure the Environment variables and function code
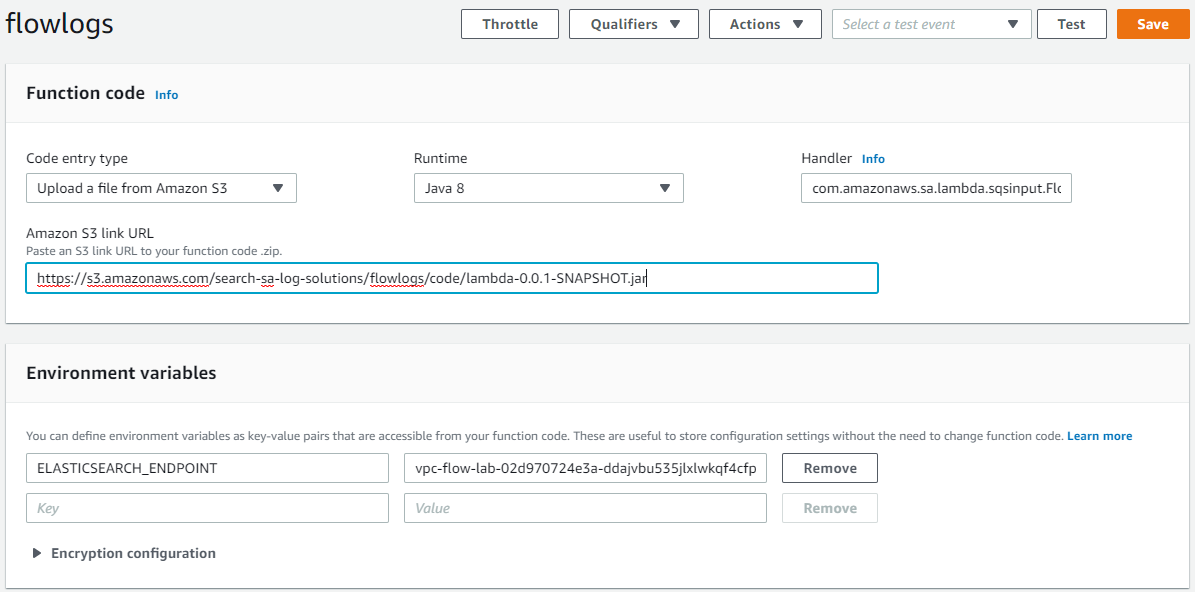
You will need to pass in the Amazon Elasticsearch domain endpoint so that the Java code can communicate with Elasticsearch using the Java High Level Rest client. Earlier in the lab, you copied the endpoint for the domain. You will use that endpoint in this configuration. Scroll down to the Environment variables section and create a key named ELASTICSEARCH_ENDPOINT. Use the value from the output section in the CloudFormation template for the creation of the Elasticsearch cluster.
Now configure the code. In the dropdown under the Function code, select “Upload a file from S3”. Paste the following URL in the link section.
https://s3.amazonaws.com/search-sa-log-solutions/flowlogs/code/lambda-0.0.1-SNAPSHOT.jar
Save the configuration changes so that do not get lost.
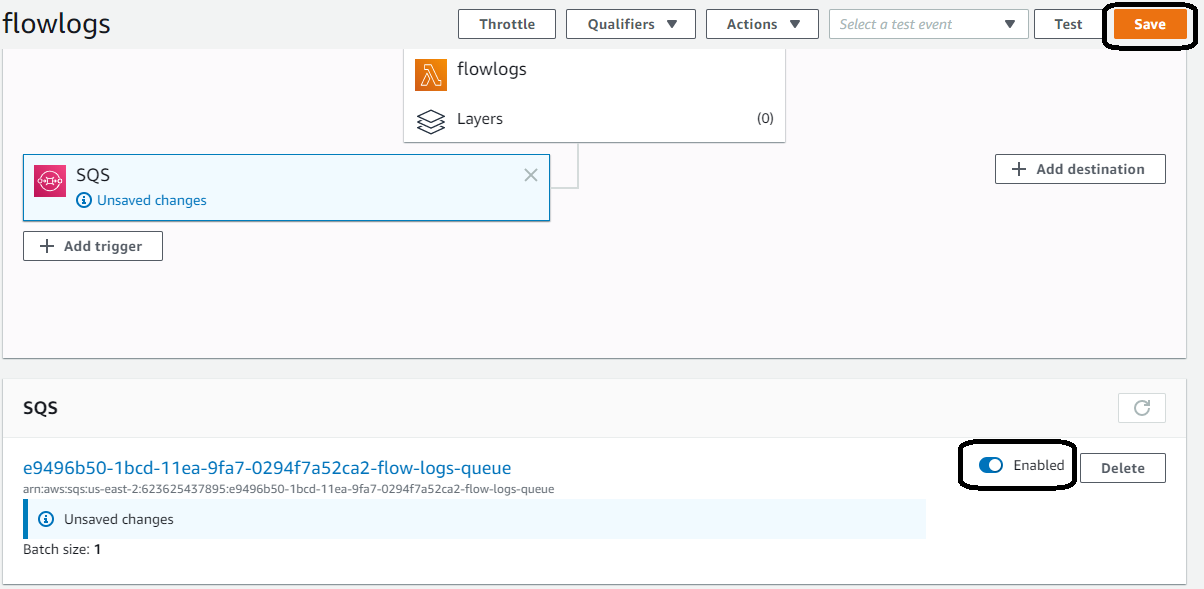
Enable the function to receive requests from SQS
Now that you configured the function, it is time to run it. Enable Lambda to read from SQS. Save the configuration.
Monitor the function to ensure data is flowing
Under the monitoring tab, ensure that you have events and invocations. If you jump to view the logs in CloudWatch, details on the invocations are present.
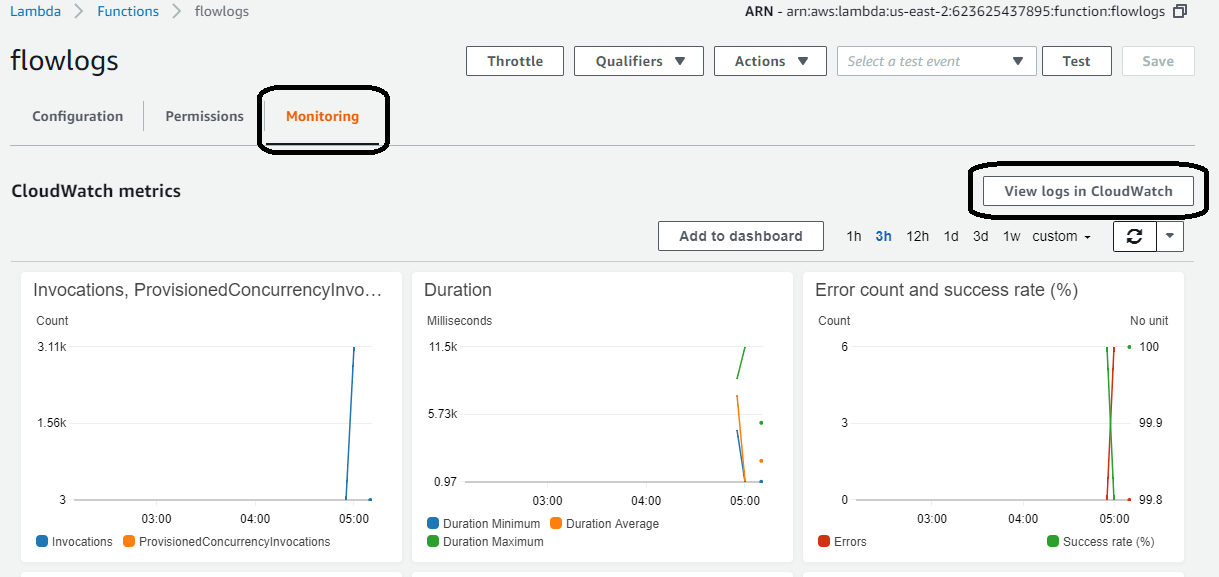
Click on the “View logs in CloudWatch” button and click on any of the log output to see what the code is doing:
Click on one of the logs to reveal details such as these:
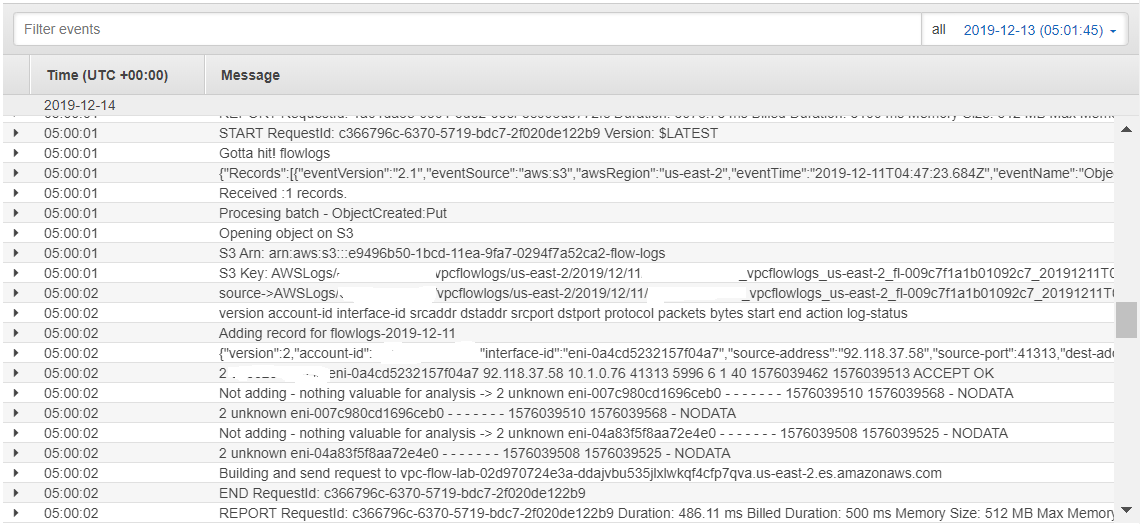
Now you have data flowing to Elasticsearch. The logs do not indicate any errors, so let us verify that is the case.